1. Overview
AWS Neuron 是一个为了 AWS inferential 和 AWS Trainium 芯片设计的 SDK。它提供了一整套工具用于运行 deep learning 和 generative AI 任务。这个SDK 包括了 compiler, runtime, training and inference libraries, and profiling tools。现在业界部署模型一般都是使用 GPU,而 Neuron 算是提供了另一种选择,用户可以使用 SDK 在这些 AWS AI Chip 上部署自己的模型。 [reference]
2. Neuron Software Stack
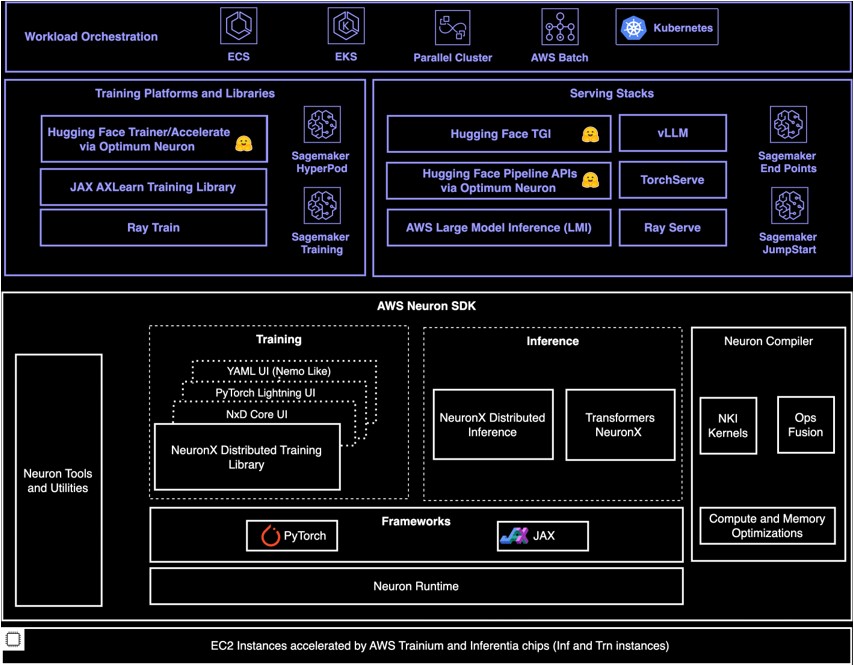 上面这张图[source] 很好的列出了 Neuron 相关的生态链。Neuron SDK 里面分为那么几个大块,Inference/Training Libraries, Frameworks, Compiler, Runtime, Tools。
上面这张图[source] 很好的列出了 Neuron 相关的生态链。Neuron SDK 里面分为那么几个大块,Inference/Training Libraries, Frameworks, Compiler, Runtime, Tools。
2.1 Inference/Training Libraries
从一个使用 neuron sdk 来部署模型的角度来说,这一部分的东西是开发者更容易直接接触的,它们本身已经支持了一些模型例如 llama,mistral 等,所以开发者如果只是使用这些 open source 的模型,就可以直接使用。
对于 Inference 来说,主要使用的是 Transformers NeuronX 和 NxD Inference, 它们都是开源的 Pytorch-based inference library。
- Transformers NeuronX 出来的比 NxD Inference 早,所以一些 feature 和 support 应该相对成熟,例如现在 vLLM 只和 Transformers NeuronX Integrate 了。
- NxD Inference 在官网上还写着 Beta,不过相信不久也能把 Transformers NeuronX 有的 feature 也 enable 了,它的一个优势是拥有了 distributing inference 的能力,并且可以支持 custom NKI Kernel。
对于 Training 来说,主要使用的是 NxD Training 这个 library,没有亲身使用过,就不多说了。
另外可以提一点是, inference 和 training 很多的 code 是可以 share 的,NxD Inference 和 NxD Training 都是 based on NxD Core 这个 library 的。
2.2 Frameworks
Pytorch Neuron, JAX Neuron, TensorFlow Neuron 都是属于这一块。这些 library 方便了开发者把原生的 PyTorch 等模型 在 Neuron Device 上运行,减少了迁移成本。
2.3 Compiler
Compiler 的作用是接收 ML models (可以是 Pytorch,TensorFlow, XLA HLO) 等,然后对它进行优化生成一个可执行文件 NEFF (Neuron Executable File Format)。然后这个 NEFF 可以被 Runtime 使用。
2.4 Runtime
Runtime 由 kernel driver 和 C/C++ libraries 构成,由于我没真的接触,不多说。大概知道它用于 load compiler 的产物(NEFF) 以及和 Neuron 硬件沟通,例如分配硬件资源、调度计算任务等就好了。
2.5 Tools
Tools 分为两类
- Monitoring Tools: 用于 collect neuron 运行时候的一些信息,例如 NeuronCore and vCPU utilization,memory usage 等
- Profiling Tools: 更 focus 模型运行时候的表现,例如开发者可以用这些来观测模型在 inference 的 prefilling, token generation 的各个步骤的 latency,硬件的使用情况等,来帮助开发者优化模型的 througput,latency 等。
3. A Closer Look at Transformers NeuronX
3.1 Overview
稍微深入看一眼 Transformers NeuronX 这个 lib。作为一个之前没有真正做过 ML 的人,刚开始 debug 这些代码的时候困扰我的一个点是,我并不清楚 XLA HLO 是干什么的,经常断点走着走着不清楚走去哪了。所以为了便于理解,我后来把这个 lib 里面的代码分成了两部分。
- Part1: Logic Running on the CPU. 这一部分就像其他的 python 代码一样,可以用 python 断点来 debug,非常 general SDE 友好。
- Part2: Logic Running on the Neuron Device. 一些大量计算并且可并行的操作我们需要 run on neuron device,这部分会先用 HLO 定义成计算图,然后 compiler 把它编译成 NEFF,然后在 inference 的时候 python 代码可以把它当成一个黑盒来执行。
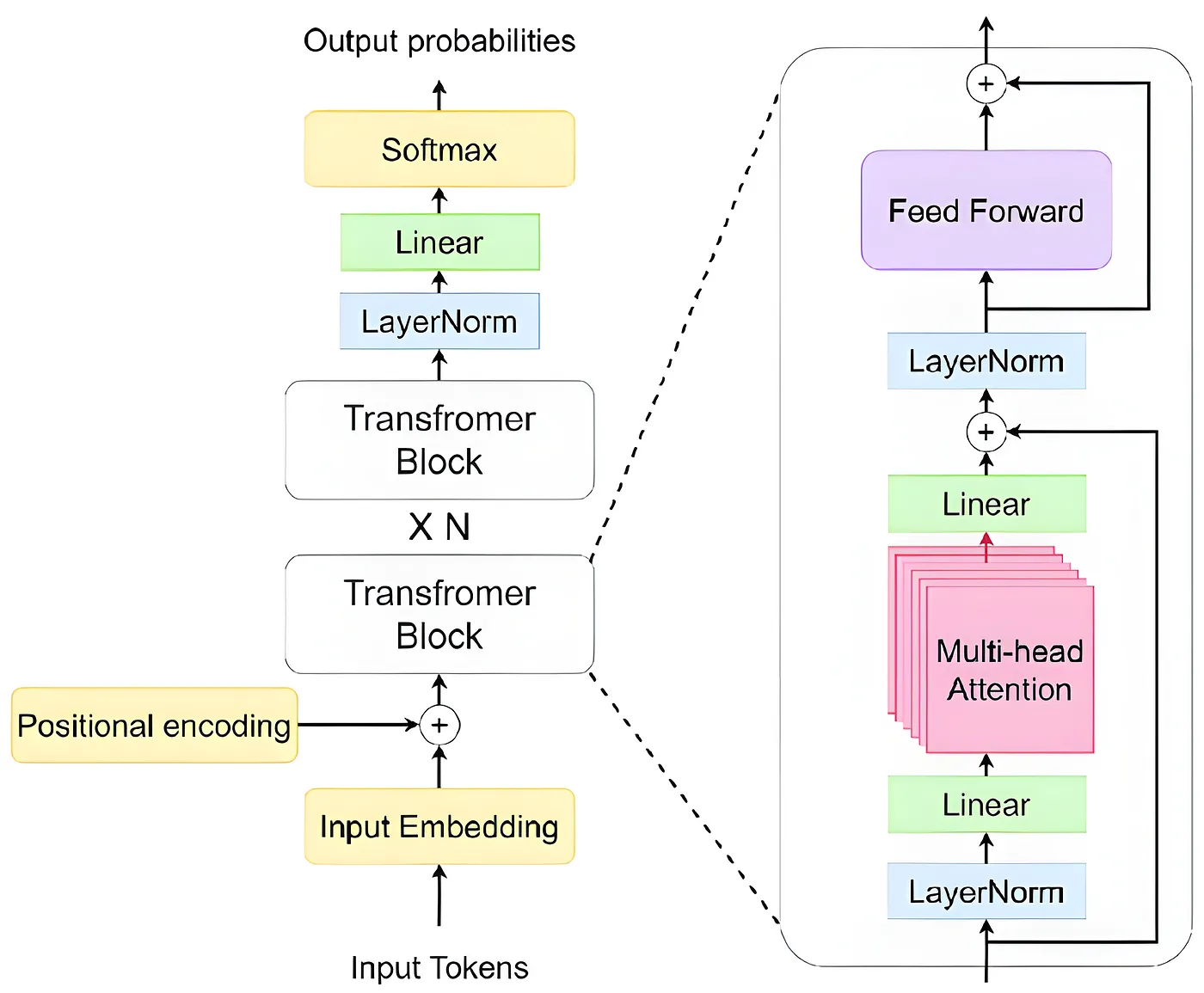 https://arxiv.org/pdf/2305.07716
https://arxiv.org/pdf/2305.07716
举个例子,上面是一个 decoder only 的 transformer 架构,在对这个模型做 inference 的过程中,计算量主要来自于 Transformer Block 的 N 次计算。以 llama 3 70b 为例,N = 80,所以这是非常大量的计算,这时候就是需要 GPU 或者 Neuron 来并行计算,加速整个过程。
而这个 lib 已经 implement 了各种模型的架构,在 load 模型的时候,这些大量计算的步骤会被构建成计算图,并经过 compiler 编译成 NEFF 文件,NEFF 文件在 inference 时会被 Runtime 使用,实现 neuron device 的利用和并行计算。
除了提供模型的加载和并行计算,它还会提供一些其他的功能以便开发者可以直接使用。例如:
- Preprocessing: 例如把输入的文本变成 token,把输入包装成计算图可以使用的 format (Context Encoding, Token Generation, Batching, Speculative Forward 等计算图所需要的 input 是不一样的)
- Postprocessing: 例如把输出的 probabilities 进行 sampling 获取 token,判断一个回答是否生成结束(EOS token),streaming 等。
这些步骤通常不是并行计算,debug 的时候也相对容易。
3.2 Code Example
import time
import torch
from transformers import AutoTokenizer
from transformers_neuronx import LlamaForSampling
# load meta-llama/Llama-2-13b to the NeuronCores with 24-way tensor parallelism and run compilation
neuron_model = LlamaForSampling.from_pretrained('Llama-2-13b', batch_size=1, tp_degree=24, amp='f16')
neuron_model.to_neuron()
# construct a tokenizer and encode prompt text
tokenizer = AutoTokenizer.from_pretrained('Llama-2-13b')
prompt = "Hello, I'm a language model,"
input_ids = tokenizer.encode(prompt, return_tensors="pt")
# run inference with top-k sampling
with torch.inference_mode():
start = time.time()
generated_sequences = neuron_model.sample(input_ids, sequence_length=2048, top_k=50)
elapsed = time.time() - start
generated_sequences = [tokenizer.decode(seq) for seq in generated_sequences]
print(f'generated sequences {generated_sequences} in {elapsed} seconds')
可以看到这个代码还是很短的 source
- 第一部分就是 load llama模型,根据输入的参数不同 (例如 batch size=1),计算图会在这时候被生成和编译,并且生成 NEFF 文件。
- 第二部分是 load tokenizer 并且生成 input tokens
- 第三部分就是调用 neuron_model 并生成 response
以这个为 starting point 并且记得 3.1 所说的两部分,就可以尝试 run 一个模型的 inference task 然后更深入的往下看代码了。
4. Closing Notes
这还是一篇写给自己看的随笔,回想这一两年,确实学习到了挺多东西。在使用这些 SDK 的过程中,记得一开始很容易陷入 debug 的 旋涡,因为当时过于关注细节,没有一个 big picture。回头看,实际上一开始就问问自己整个 workflow 是怎么 work 的,就算一开始还是什么都不懂,在遇到 blocker 的时候也会更容易找到往哪个方向去探索。
Ok cool, 这个工作就算告一段落,相信以后 Neuron SDK 也会不断迭代,并且有更多新的 feature。看看它可以不可以 抢下 GPU 的一块蛋糕吧。