1. Introduction
Parallel Decoding 是一种对 LLM Inference 加速的一种方法,这个随笔聊一聊它是怎么 work 的,并且聊一下它的几个流派。
2. What is Parallel Decoding
这一 part 聊聊什么是 Parallel Decoding 以及为什么它为什么能够 LLM Inferece 加速。
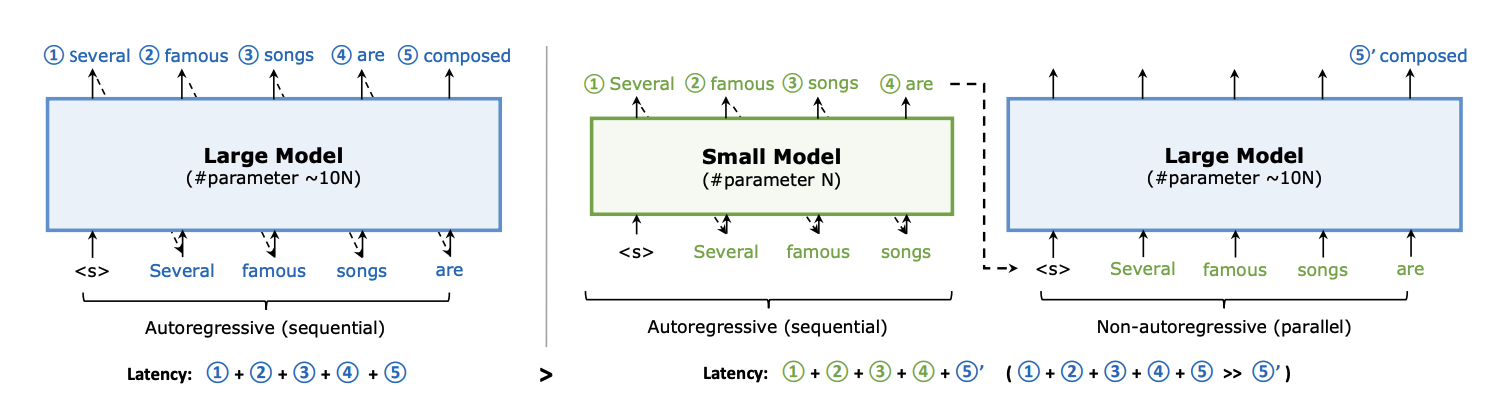 ref: https://arxiv.org/pdf/2302.07863
ref: https://arxiv.org/pdf/2302.07863
传统的 llm model 会用 autoregressive 的方式一个个生成 token。也就是说如果需要生成 5 个 token 就需要调用大模型 5 次,每生成一个 token 都依赖之前的输出。
而 Parallel Decoding 则利用了小模型和大模型协作的方式,由小模型先生成多个token (例如 4个),然后由大模型对它们进行 validation 并且也生成一个 token。如果所有小模型生成的 token 都被大模型接受了,那么生成 5 个 token 的时间就变成了 4 次小模型推理加上 1 次大模型的推理,小模型的推理时间低于大模型,由此总体时间会更快。
上面只是说的理想情况,如下图所示,一般情况下不会所有 token 都被 accept,一些 token 会被 reject,然后 target model regenerate 这个被 reject 的 token,然后进行下一轮 decode。
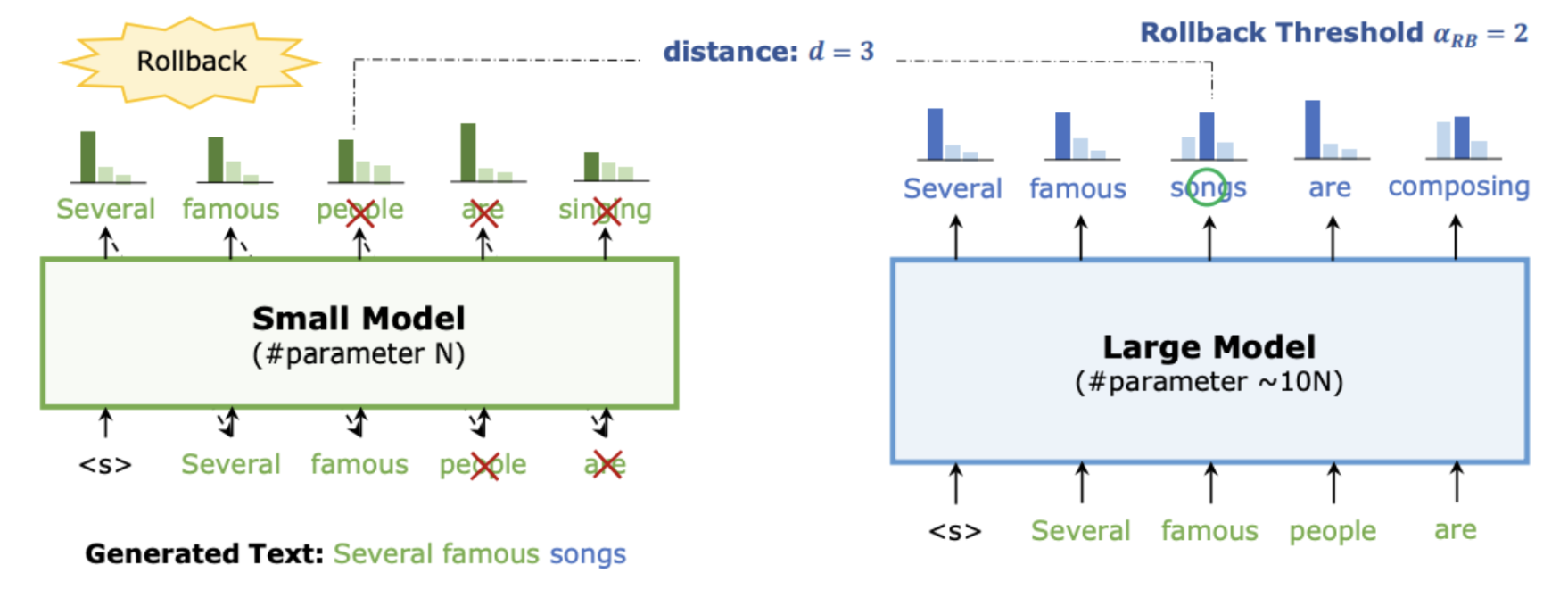 ref: https://arxiv.org/pdf/2302.07863
ref: https://arxiv.org/pdf/2302.07863
在后面的章节里,我们把这个大的模型叫 target model,这个小的模型叫 drafter,并且我们可以把 Parallel Decoding 分成这样三部分:
- Drafting: The draft model produces a set of potential tokens for the next sequence position, considering the previous context. 此时的输出是 draft tokens,以及 draft tokens 所对应的 logits。
- Validation: The target model performs a single forward pass to calculate the probability of each draft token given the current context. 输入 draft tokens,输出的是 target logits。
- Sampling: The process of selecting the final tokens based on the validation results. 输入是 draft tokens, draft logits 和 target logits,最终输出想要返回给用户的 tokens。
3. Evaluating the Speedup Achieved by Parallel Decoding
假设:
- 生成一个 token,原始大模型(target)的前向传播时间为 \(T_{\text{target}}\);
- 总共需要生成 \(N\) 个 token,那么传统自回归生成的总 latency 为
\[ T_{\text{auto}} = N \times T_{\text{target}} \]
而并行解码的过程可以分为三个阶段:
- Drafting: 小模型生成 draft token 的时间为 \(T_{\text{drafting}}\);
- Validation: 大模型 validate 这些 draft token 的时间为 \(T_{\text{validation}}\);
- Sampling: 最终从 draft token 中采样确定输出的时间为 \(T_{\text{sampling}}\);
那么单次 Parallel Decoding 的 latency 为
\[ T_{\text{parallel_iteration}} = T_{\text{drafting}} + T_{\text{validation}} + T_{\text{sampling}} \]
如果一次并行生成 \(k\) 个 token,则总的并行解码延迟为
\[ T_{\text{parallel}} = \lceil N/k \rceil \times \Big( T_{\text{drafting}} + T_{\text{validation}} + T_{\text{sampling}} \Big) \]
为量化延迟提升(或加速比),我们可以定义速度提升因子(Speedup)为:
\[ \text{Speedup} = \frac{T_{\text{auto}}}{T_{\text{parallel}}} = \frac{N \times T_{\text{target}}}{\lceil N/k \rceil \times \Big( T_{\text{drafting}} + T_{\text{validation}} + T_{\text{sampling}} \Big)} \]
只有当 \(\text{Speedup} > 1\) 时,Parallel Decoding 会给我们带来提升。
4. Naive vs Mudusa vs Eagle2 [In Progress]
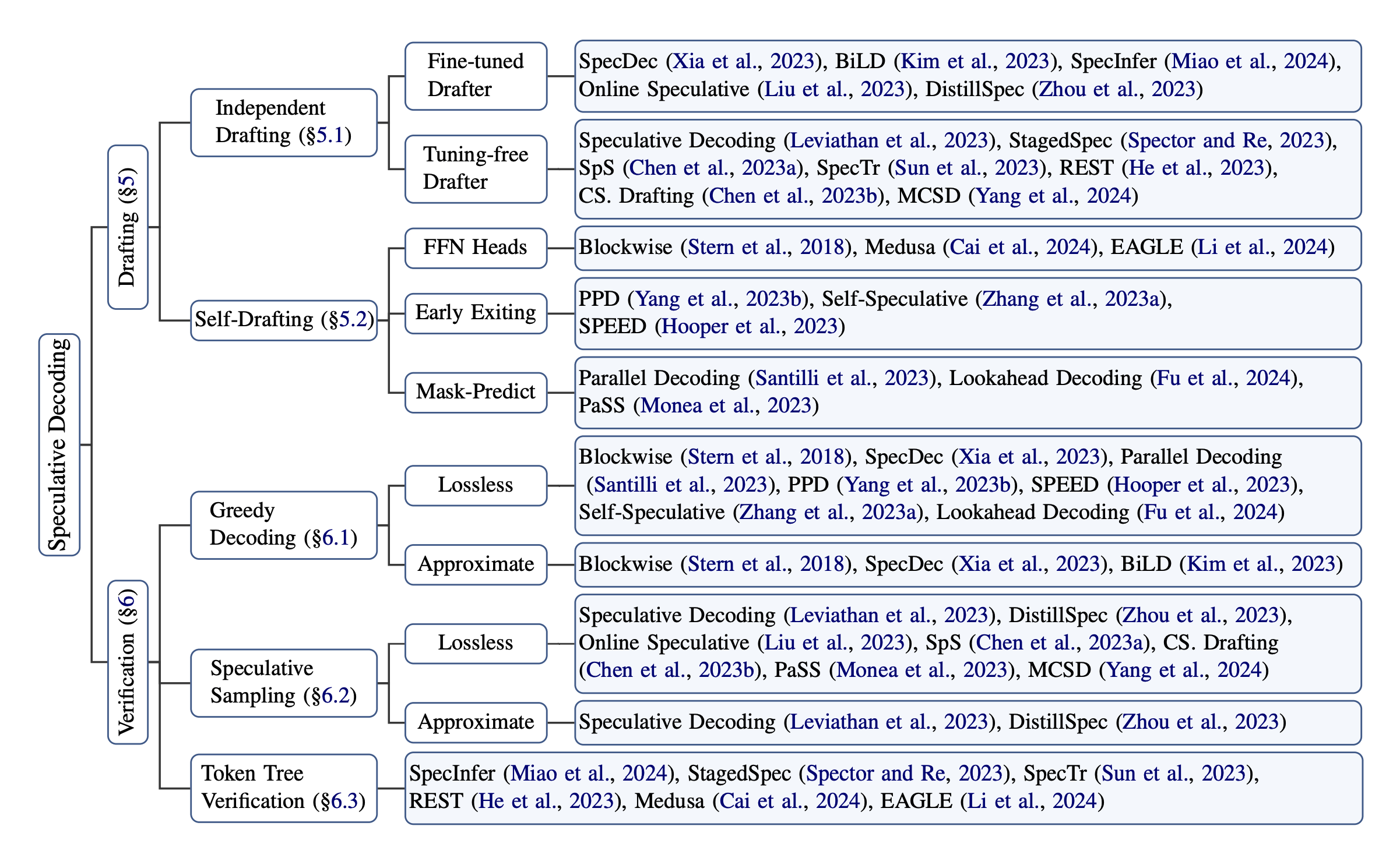 ref: https://aclanthology.org/2024.findings-acl.456.pdf
ref: https://aclanthology.org/2024.findings-acl.456.pdf
根据 drafting 和 verification 的不同,Parallel Decoding 有非常多的变种,除了原始的 speculative decoding,后面比较受到关注的是 Medusa 和 Eagle2,理论上来说 Eagle2 对于对于 performance 的提升是最好的,这章就主要聊聊这三种方式的不同实现和各自的优缺点。
4.1 Drafting
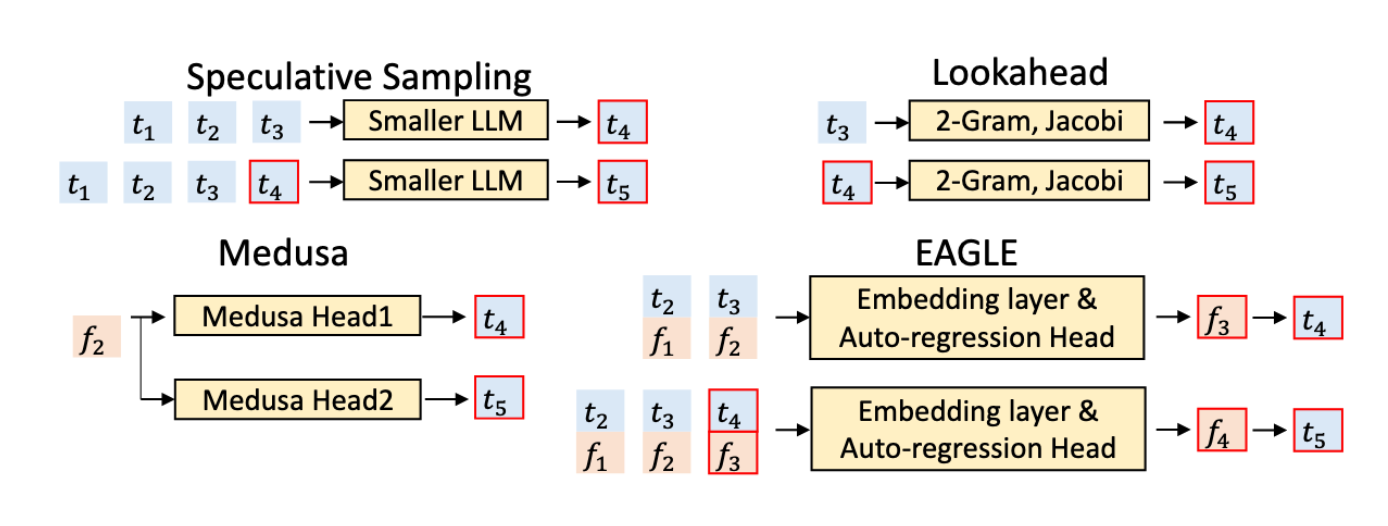 ref: https://zhuanlan.zhihu.com/p/15955544919
ref: https://zhuanlan.zhihu.com/p/15955544919
Naive Speculative Sampling
- drafter 是一个比 target model 更小的模型,例如对于 llama70b 来说,llama3b 就可以是它的 drafter
- drafter 每次 iteration 的输入是 token 输出也是 token,经过 k 次 iteration 生成 k 个 token。
Medusa
- drafter 是训练出来预测第 1, 2, xx, k 个 token 的k 个不同的 mudusa head
- drafter 的输入是 second-to-top-layer feature, 而不是单纯的 token,一次 iteration 可以同时生成 k 个 token
Eagle2
- drafter 是训练出来的 Autoregression Head
- drafter 的输入也是特征层的特征,由 Autoregression Head k 次 iteration 才能生成 k 层 token。这边说了是 k 层 token, 形式是一个 dynamic draft tree,利用了 tree attention,每次 drafter 的 forward 会生成一个 tree layer
4.2 Validation & Sampling
这个 part 大致说一说为什么 Parallel Decoding 说可以不牺牲 quality。
先看一看 LLM 每生成一个 token 都在做什么:
- 每一步生成中,LLM 会输出一个针对所有可能下一个 token 的概率分布。
- 然后从这个分布中采样出一个 token。
那在 Parallel Decoding 中我们是怎么做的呢:
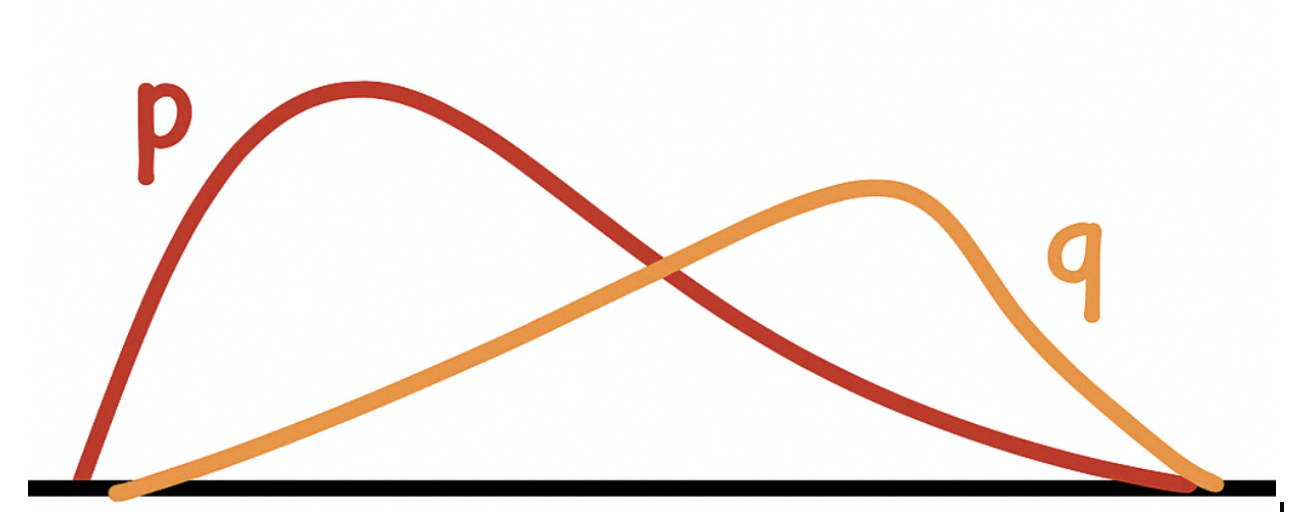
- 草稿阶段(Drafting Stage): draft model 会为每个 token 提供一个概率分布 \(p(x)\)。
- 验证阶段(Verification Stage): target model 会重新计算出它自己对这些 token 的概率分布 \(q(x)\)。
- 采样阶段(Sampling Stage): 根据这两个分布决定是否接受草稿中的 token:
- Case1: 如果 \(q(x) \geq p(x)\),则直接接受该 token。
- Case2: 如果 \(q(x) < p(x)\),则以 \(\frac{q(x)}{p(x)}\) 的概率接受该 token,否则拒绝并从 \(q(x)\) 中重新采样。
 ref: https://www.youtube.com/watch?v=S-8yr_RibJ4
ref: https://www.youtube.com/watch?v=S-8yr_RibJ4
这样做可以让从 Parallel Decoding 采样出来的 token 概率分布和原始的模型一致。
4.3 优缺点
Naive Speculative Sampling
- [优点1] 对于 open source 的模型来说,drafter 不需要自己训练也可以找到,例如 llama3b 对于 llama70b
- [优点2] 在 non-greedy decoding 的时候可以保证输出分布和 target model 一致
- [优点3] 实现相对简单,工程成本相对低。
- [缺点] 对 performance 的提升不如下面两位
Medusa
- [优点] 与 Naive 相比,可以在一次迭代中并行预测多个 token,因此通常有更好的加速效果。
- [缺点1] 对 performance 的提升虽然比 Naive 的要好,但是不如 eagle2
- [缺点2] 没法在 non-greedy decoding 的时候可以保证输出分布和 target model 一致
- [缺德3] 需要自行训练 drafter
Eagle2
- [优点1] 现阶段对 performance 提升最好的 parallel decoding 方法
- [缺点1] 需要自行训练 drafter
- [缺点2] 实现相对复杂,因为涉及 dynamic tree 的东西
暂时来看,如果想要快速用 Parallel Decoding 来加速一个 model 的 inference,可以考虑 Naive Speculative Decoding, 如果想要追求最好的效果,应该选择 Eagle2。
4.4 Tree Attention for Eagle
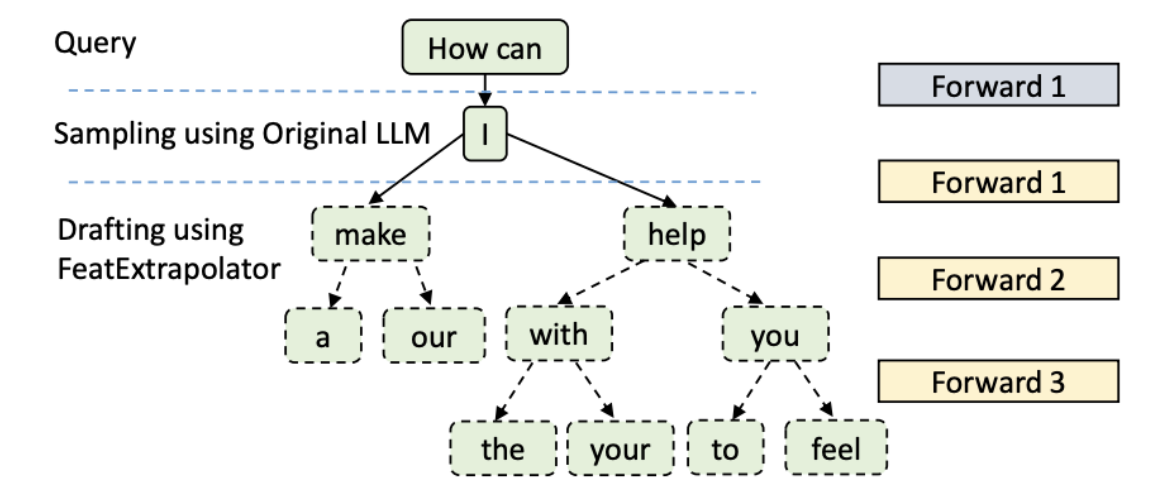
既然 Eagle 是当前的 SOTA(最先进方法),我们有必要来聊一下它的 Tree Attention(树状注意力机制)。
- 在 Drafting 阶段,每一次 forward() 调用都会生成多个 token,就像上图所示。
- 在 Validation 阶段,Target LLM 会通过一次 forward 计算就可以 validate 整体树中所有的 token。
这样做可以提升每个 iteration 被接受的 token 数量,从而进一步加快了推理速度。
 ref: https://arxiv.org/pdf/2406.16858v1
ref: https://arxiv.org/pdf/2406.16858v1
5. Challenges
- Compute Bound Transition: 当 batch size 变大时,decode 的阶段有可能会从原本的 memory bound 转向 compute bound,而这时 Parellel Decoding 就可能失效
- Higher TTFT: 虽然 Parallel Decoding 可以帮助减小 TTIT, 可是也会增加 TTFT 的 latency,从而使得在一些情况没办法真的投入使用。
- Draft Model Training: 需要具备训练 draft model 的能力
- Extra Overhead: 虽然说最重要的 latency 还是来源于 validation part,drafting,sampling 等步骤有时也会带来挺多的latency,特别是当 batch 增加一种,也需要对它们进行优化
- Integration Complexity: 它需要一直和其他技术适配,例如 PD 分离,Batching,Paged KV 等等,所以在真实应用的时候可能会需要解决这些问题。
- More: 上面就是我想到的一些挑战,那在具体部署的过程中一定还有很多其他的问题。
6. Closing Notes
Parallel Decoding 还真是一个很神奇的技术,需要涉及系统,也涉及算法。既要考虑怎么和系统里其他的优化 integrate 在一起,也需要考虑怎么训练一个好的 draft 模型,并且在不同硬件中的表现也非常不同。学习和实践它对于我来说是一个宝贵的机会,帮助我往下窥探了很多 ML System 的内容。当我真正写完这篇东西的时候 Eagle3 也发布了。如果后面有新的发现和感想希望可以写第二篇随笔 follow up 一下 Parallel Decoding 的发展吧。