1. 前言
在 LLM Inference 中,整个流程通常会分为两个阶段: Prefill (处理 input prompt 并生成第一个 token) 和 Decode (逐步生成后续 tokens) 两个阶段。传统做法是让两个阶段在同一个机器上串行完成,而 PD Disagg 则把它们拆到不同机器上执行,从而提升推理性能。
这篇博客主要聊三个点:
- PD Disagg 的 Motivation
- PD 实现思路
- 开源框架的概览
个人推测:在需要 handle 大量 traffic 的情况下, PD Disagg 和 batching 一样,逐渐成为 LLM Inference 的基础优化手段被大量使用。
2. Motivation
- 独立优化 Prefill & Decode: 当 P 和 D 在用一台机器的时候,优化时需要同时考虑 P 和 D 的性能,分开以后就可以独立优化。
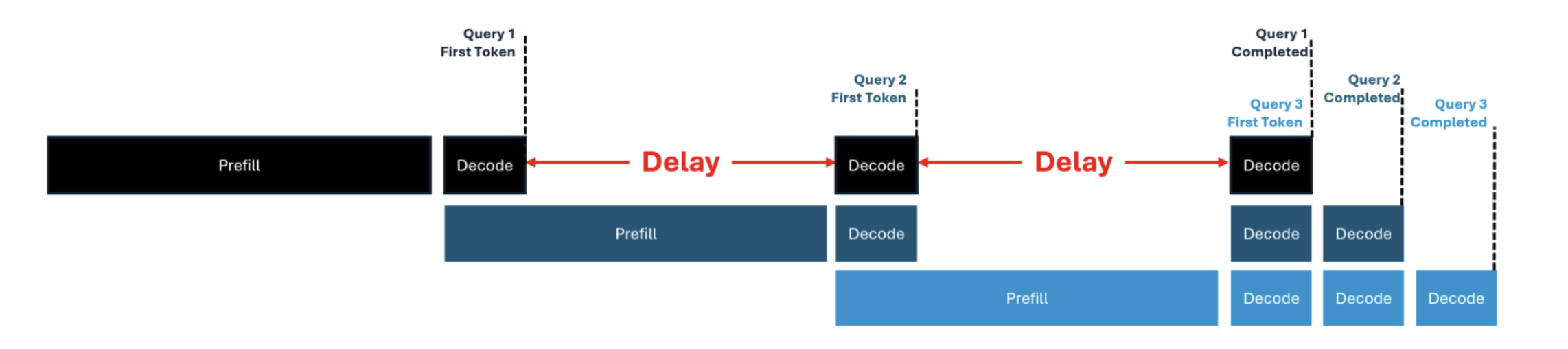
- 消除 Prefill 对 Decode 的干扰: 如下图 (refer) 所示,当使用了 Continuous Batching 的时候,如果 P 和 D 在一台机器上,新来的 request 需要做 prefill,并且 prefill 要花很久,会增加 decode 的 latency,并且 batch size 越大越明显。Disagg 直接把 P D 分开在两个机器上,自然就消除了这个问题。(Side Note: Chunked Prefill 也是一种方法来缓解这个问题,但是这里不深入讨论)
3. 实现思路
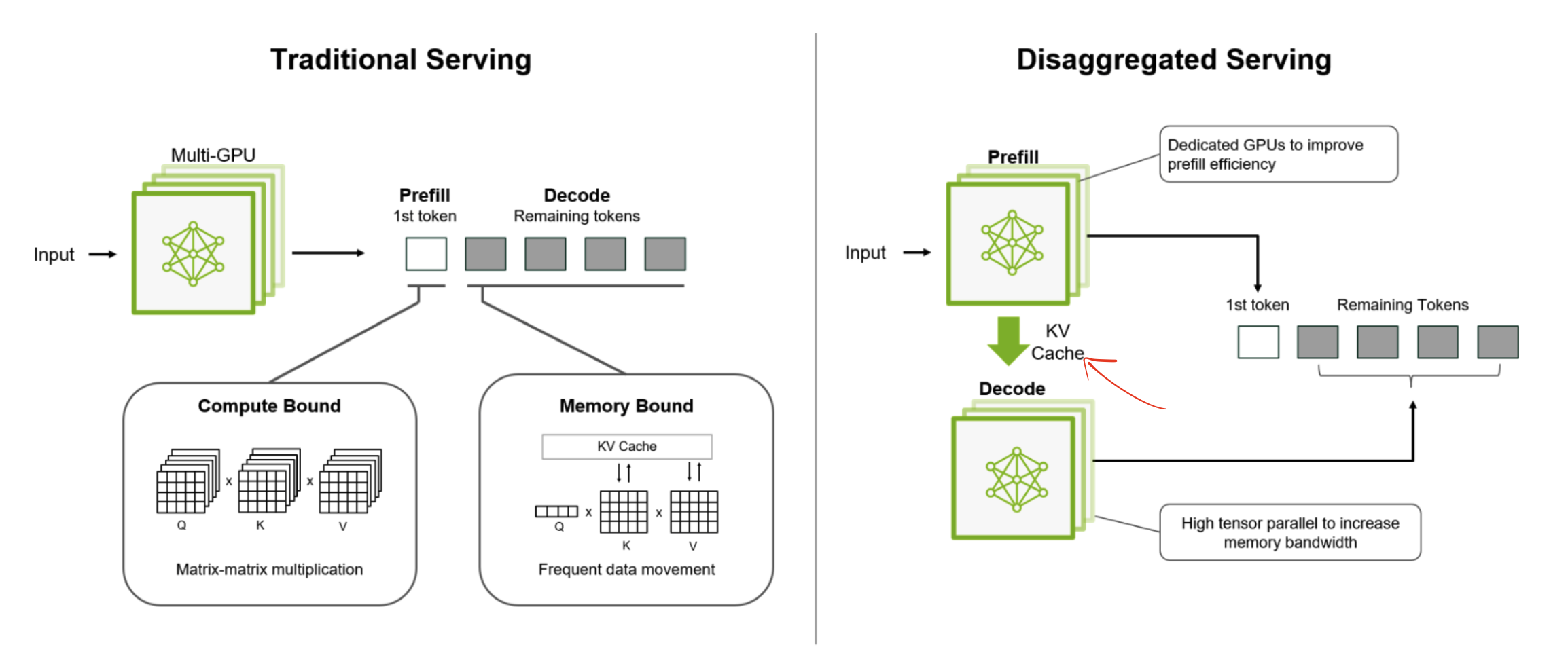 借用一下这个 NVIDIA Blog(refer) 的图,分开了 Prefill 和 Decode 之后增加的一个重要步骤就是 KV Cache 的传输。KV Cache 是可以挺大的,举个例子,对于 llama-3.1-70B-Instruct,如果用 bf16,input length 是 4096 的情况下,一个 request 的 KV Cache 可以是 1.25 GB(KV Cache 计算工具)。所以传输 KV Cache 的效率就很重要了。
借用一下这个 NVIDIA Blog(refer) 的图,分开了 Prefill 和 Decode 之后增加的一个重要步骤就是 KV Cache 的传输。KV Cache 是可以挺大的,举个例子,对于 llama-3.1-70B-Instruct,如果用 bf16,input length 是 4096 的情况下,一个 request 的 KV Cache 可以是 1.25 GB(KV Cache 计算工具)。所以传输 KV Cache 的效率就很重要了。
3.1 伪代码
让 GPT 写了一下伪代码
# prefill node
def handle_prefill(request):
input_ids = request["input_ids"]
req_id = request["id"]
# model 对整个输入执行 forward 计算
kv_cache, last_hidden = model.prefill(input_ids)
# 把 result 发送给 decode node
connector.send(req_id, kv_cache, last_hidden)
# decode node
def handle_decode(req_id):
# 等待接收 prefill 的 result
kv_cache, hidden = connector.receive(req_id)
output = []
next_token = sample_from(model.lm_head(hidden))
output.append(next_token)
# decode 直到这个 request 生成完所有的 token
while not finished(output):
hidden, kv_cache = model.decode_one(next_token, kv_cache)
next_token = sample_from(model.lm_head(hidden))
output.append(next_token)
return output
3.2 kv cache 传输需要学习的概念
真不是很懂,大概列个要学习的提纲吧,让 chatgpt 按层级给我生成了一个图,AI 真是太强了
┌────────── Dynamo ─┐ ← 调度 / 批处理 / 控制
│ vLLM │
│ SGLang │
└──────────┬─────────┘
(API: send_kv / recv_kv)
┌──────────┴─────────┐
│ NIXL LMCache Mooncake │ ← 懂 KV 的搬运工
└──────────┬─────────┘
(calls P2P/collective verbs)
┌──────────────────┴──────────────────┐
│ NCCL RCCL UCX libfabric NVSHMEM │ ← GPU 通用通信库
└──────────────────┬──────────────────┘
(runs over physical links)
┌──────────────────┴──────────────────┐
│ NVLink/NVSwitch PCIe RDMA‑NIC ETH │ ← 铜线 / 光纤 / 交换芯片
└─────────────────────────────────────┘
# Comment from GPT: 一句话总结
硬件给上限,底层给通道,中层给“KV 专线”,上层给业务逻辑。
换芯片/换网络时,先问 “最底层库能否跑在这条物理链路上?”,
再把中层/上层指向新的后端,PD 拆分就能继续平稳跑下去。
3.3 一些其他工程上的决策
真正应用到工程上时,还是很多细节要决策。鉴于我也没实践过,大概先说几个我想到的要考虑的地方,之后再补充:
- 通信入口:是由 decode 还是 prefill 直接和外部通信,这是两种不同的方法,直觉上来说先 prefill 再 decode,用 prefill node 来对外沟通,同时能得到更好的 TTFT 。但是 decode 作为入口也有它的好处,比如在 streaming 的情况下,后序大量的 token generation 不需要经过 prefill node 通信,省下了一些中间的 latency。
- prefill & decode node 的比例:最理想状况就是 prefill 和 decode 同时满负荷运行。但是在实际情况下,不同的 batch size,input length, output length,以及硬件都是重要影响因素。需要结合实际的情况调试出来一个最优的 prefill 和 decode 比例。
- 如何选择不同的通信协议和硬件库:这个我不懂,但是理应是一个选择
- Load Balance:毕竟 Prefill 和 Decode 被拆分成两个独立服务,部署在不同机器上,load balance 如果做不好的话一定会影响硬件的利用率,所以也是一个需要关注的地方。
- etc.
4. 开源框架概览
Nvidia Dynamo
性能挺好,不过应该对自身硬件的支持和优化是最好的
vLLM & SGLang
这俩是 llm inference 开源社区里做的最好的两个项目了,现在也都在支持 PD Disagg,写的时候应该都还处于快速开发,没有到稳定完成的阶段,值得后面的跟进。
- vLLM PD Disagg Roadmap: https://github.com/vllm-project/vllm/issues/10818
- SGLang PD Disagg Roadmap: https://github.com/sgl-project/sglang/issues/4655
Mooncake & LMCache
这俩也是值得关注的项目,也先列在这里
- Mooncake: https://github.com/kvcache-ai/Mooncake
- LMCache: https://github.com/LMCache/LMCache
5. 总结
推测 PD 分离会是未来大规模应用 LLM 的基础的技术,这个领域还在快速发展,值得追踪和学习,让我们拭目以待。
6. Refer
- https://docs.vllm.ai/en/stable/features/disagg_prefill.html
- https://developer.nvidia.com/blog/streamlining-ai-inference-performance-and-deployment-with-nvidia-tensorrt-llm-chunked-prefill/
- https://developer.nvidia.com/blog/introducing-nvidia-dynamo-a-low-latency-distributed-inference-framework-for-scaling-reasoning-ai-models