1. Overview
vLLM 是一个做 LLM inference 和 serving 的开源 library,鉴于最近有使用到它,所以趁我还没忘记可以整理一下我对它的理解。
2. Offline Inference Workflow
下面是一段简单的以 LLM 为入口的 offline inference 的示例代码 (source)
from vllm import LLM, SamplingParams
# Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# Create an LLM.
llm = LLM(model="facebook/opt-125m")
# Generate texts from the prompts. The output is a list of RequestOutput objects
# that contain the prompt, generated text, and other information.
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
可以看到 llm 是 entry point, 也是去读代码的一个很好的 starting point,从这个 level 看, llm 做了这几件事情:
- load a model, 在这个阶段准备好模型的 weight,tokenizer 等相关资源,以支持后续的 inference。
- llm 会接收传入的 prompts 和 sampling params 并且生成对应的结果
接下来,我们再往下深入一点看看 llm 内部在做什么,于是我画了一个简单的 workflow 图。
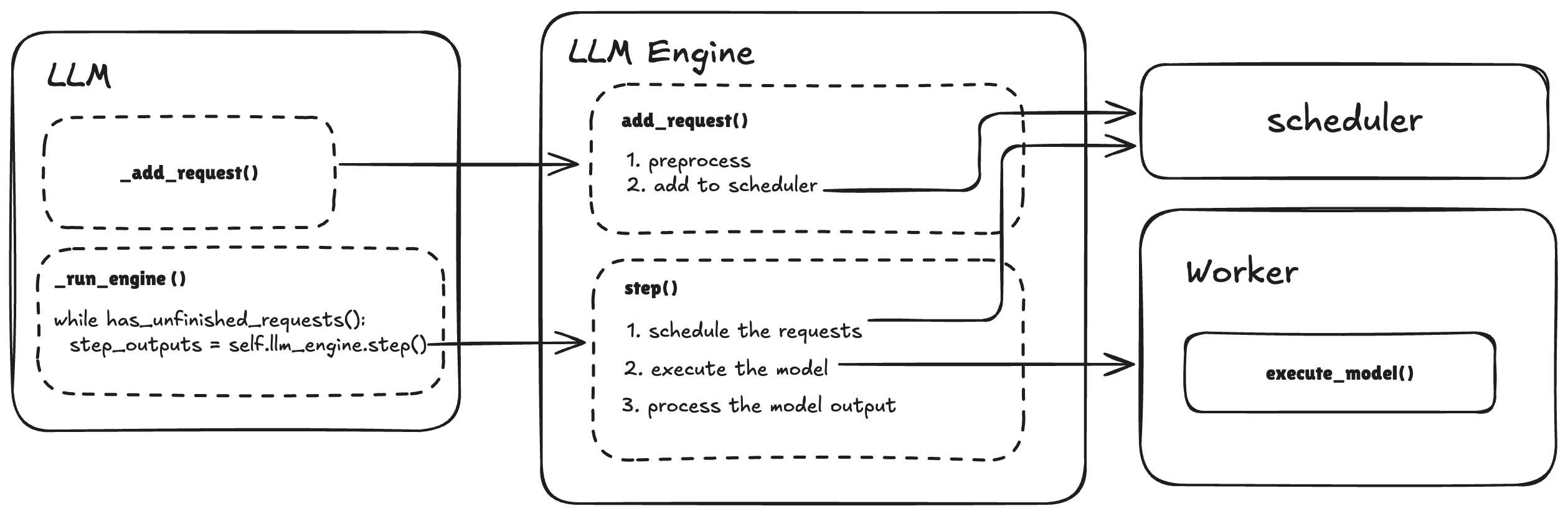 在 llm 做
在 llm 做 generate() 操作的时候,它主要是做了两块内容:
- 把 request 加入 llm_engine
- 当还有未完成的 request 的时候,维持一个 while loop 执行 llm_engine 的 step 操作
第一点比较容易理解,就是添加 incoming requests, 并且对这些 requests 进行一些包装
第二块内容 llm_engine 的 step() 可以再往里看一下,它主要在做这三件事情
- Schedule the request: 每个 iteration 可以被处理的 requests 是有限的 (受限于硬件资源、batch size 等),所以在每个 iteration,vllm_engine 会调用 scheduler,决定哪些 requests 将在这个 iteration 被处理。
- Execute the model:调用 worker 来执行一次推理,生成下一个 token。这一过程通过 GPU 或其他硬件加速器(如 AWS Inferentia、TPU 等)完成具体的计算。注: 每次推理可能同时为多个 request 生成下一个 token(batching)。
- Precess the model output: 对模型生成的 token 再进行一些处理,例如把 token 转化成 text,检测 EOS token 来判断 request 是否结束等。
3. Online Inference Workflow
下面是一段以 AsyncLLMEngine 为入口的异步处理 request 的 inference 的示例代码 (source)
>>> # Please refer to entrypoints/api_server.py for
>>> # the complete example.
>>>
>>> # initialize the engine and the example input
>>> # note that engine_args here is AsyncEngineArgs instance
>>> engine = AsyncLLMEngine.from_engine_args(engine_args)
>>> example_input = {
>>> "prompt": "What is LLM?",
>>> "stream": False, # assume the non-streaming case
>>> "temperature": 0.0,
>>> "request_id": 0,
>>> }
>>>
>>> # start the generation
>>> results_generator = engine.generate(
>>> example_input["prompt"],
>>> SamplingParams(temperature=example_input["temperature"]),
>>> example_input["request_id"])
>>>
>>> # get the results
>>> final_output = None
>>> async for request_output in results_generator:
>>> if await request.is_disconnected():
>>> # Abort the request if the client disconnects.
>>> await engine.abort(request_id)
>>> # Return or raise an error
>>> ...
>>> final_output = request_output
>>>
>>> # Process and return the final output
>>> ...
可以把 AsyncLLMEngine 对 LLMEngine 的一个异步封装,当调用 generate 方法后,这个 request 会被加入 LLMEngine 的 waiting queue,然后 AsyncLLMEngine 通过 async 的方式在 background loop 里处理 request,计算出下一个 token 后以 streaming 的方式返回给用户。
3.1 Continuous Batching
聊到 async 处理的时候,不得不提一嘴 Continuous batching, 如果没有它,多个 requests 也很难高效的异步执行。在传统 Static Batching 模式中,多个 requests 会先聚集在一起,并且等到所有 requests 处理完之后才能处理下一个请求。而不同的 request(prompt) 对应输出的 response 长度其实是差别很大的,这就会很多不必要的等待时间。例如当 batch size = 4 的时候,同时处理 4 个 requests (S1, S2, S3, S4), 当 S3 已经处理完成, S1, S2, S4 还在处理中,此时新的 request S5 到达了,它仍然需要等待所有 requests 也处理完后成才能进行处理,这种模式就会浪费很多计算资源。
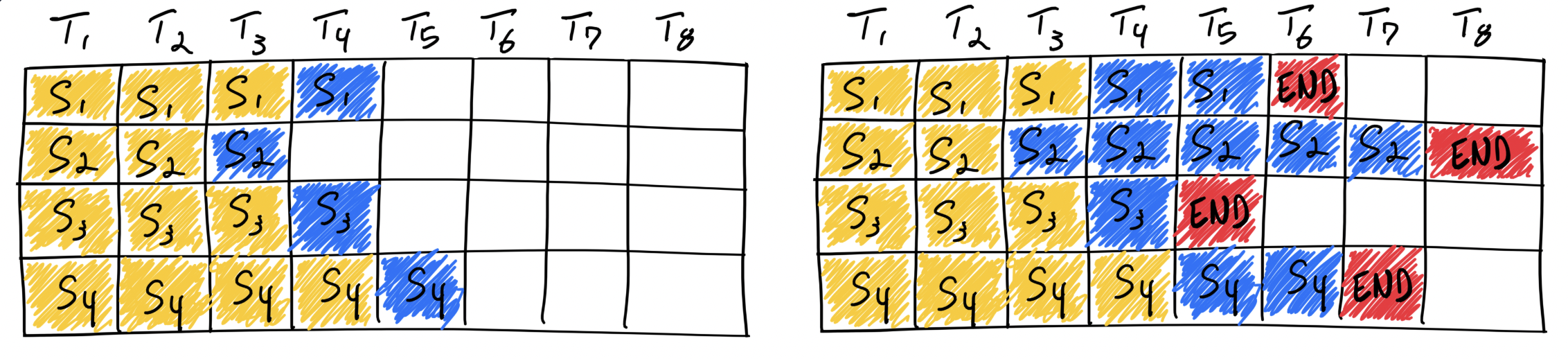 而在 Continuous Batching 中, 当我们遇到和上面例子一样的情况,当处理完 S3 之后,如果 S5 到达,它可以直接加入 S1 S2 S4 一起 处理。这样减少了 E 的等待时间,也更好的利用了计算资源。
而在 Continuous Batching 中, 当我们遇到和上面例子一样的情况,当处理完 S3 之后,如果 S5 到达,它可以直接加入 S1 S2 S4 一起 处理。这样减少了 E 的等待时间,也更好的利用了计算资源。
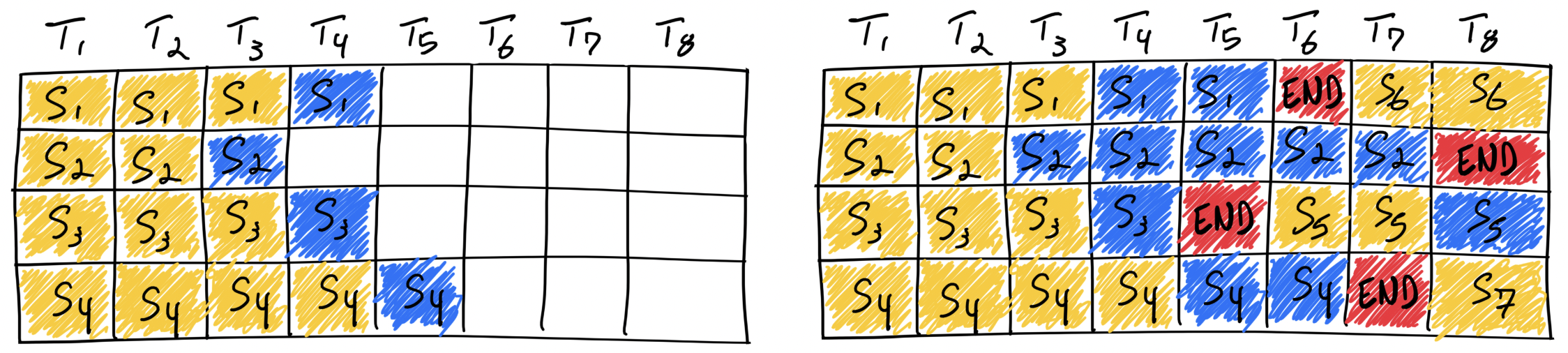 Reference: 图片出自文章 LLM Inference: Continuous Batching and PagedAttention, 里面也会更详细地描述 Continuous Batching。
Reference: 图片出自文章 LLM Inference: Continuous Batching and PagedAttention, 里面也会更详细地描述 Continuous Batching。
4. How it works with AWS InferentiaTrainium/Inferentia chips
稍微提一下这个,毕竟自己最近这段时间工作用的是 AWS Trainium/Inferentia。主要就在于 worker 在 load model 和做 execute model 的时候是基于 Neuron SDK 的了。 基于现在的时间点[1/11/2025], integrate with vLLM 的 SDK 是 transformers-neuronx , 支持的模型是 Llama 和 Mistral (reference), 并且支持了 Continuous Batching,但是暂时还没有支持 vLLM 非常关键的 Paged Attention。后面应该会支持更多的模型,以及 integrate 更多有用的 features,希望老东家的东西越做越好吧!
立一个 flag,有机会我希望能够基于 open source 和 blog 稍微深入写一点 neuron sdk 是怎么 work 的吧。
5. Closing Notes
这算是搭了这个网站以后的第一篇博客,写博客的目的也主要是为了强迫自己梳理一下自己正在做的事情,我相信输出是审视自己输入的一个非常有用的方法。这篇东西写的也没有很细节,感觉主要是为了自己看的,本身写出来的过程中也帮助我梳理了脑子中有点乱的框架,希望以后可以在开始学习和做一些事情的时候 keep in mind 我有一天得为它写个博客,以督促自己在学习的过程中更有条理和框架,不要一知半解。